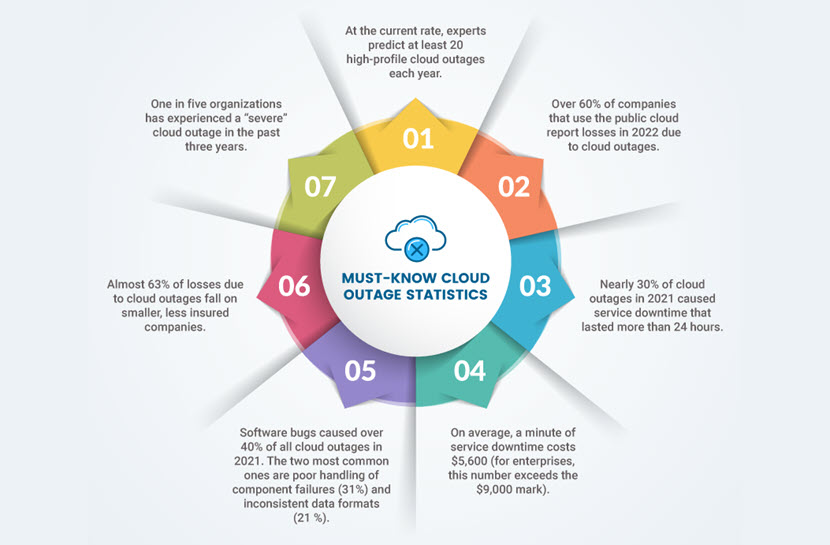
The more IT relies on cloud services, the more likely you are to suffer downtime and revenue losses due to a cloud outage. Over 60% of organizations that use the public cloud report losses in 2022 due to these incidents, so outages are not a freak occurrence companies are unlikely to face.
But are outages enough of a reason to leave the cloud for good? Or should you stick with this infrastructure type despite the risk of occasional downtime?
This article goes through everything you need to know about cloud outages. We outline their main causes, examine eye-opening stats, show how to minimize the impact of cloud downtime, and look at the most impactful outages that occurred in recent years.

What Is a Cloud Outage?
A cloud outage is a time span during which a cloud provider's services are unavailable to end-users. The vendor's infrastructure goes down (due to a bug, power failure, etc.), and the clients lose access to cloud-based assets until the provider fixes the issue.
Impact-wise, there's no difference between an on-site data center going down and a cloud outage. You lose access to IT assets in both cases, but the hands-off approach to cloud computing adds a few unique considerations:
- Cloud outages have little to no failure visibility, so users typically do not know what went wrong.
- The provider's team is responsible for fixing the error, so clients do not partake in the recovery process.
- Since you have no visibility or control over the problem, there's no way of knowing when services will go back online.
Like with local hardware, there are two types of could outages:
- Planned (typically occurs due to scheduled maintenance).
- Unplanned (happens when the provider runs into an unexpected error and must perform restoration measures).
Recent studies reveal that unplanned outages cost 35% more than planned downtime (both on-prem and in the cloud). The price difference exists because unexpected incidents take longer to identify and fix—and the longer an outage lasts, the bigger the damage.
Compared to on-site hardware, cloud-based infrastructure results in more frequent downtime but with less severity. Since no hosting system provides 100% uptime, clients are ready to tolerate occasional outages in return for cloud computing advantages. This willingness is also evident in market growth—the cloud will make 14.2% of the total global IT spending in 2024 (up from 9.1% in 2020).
If regular outages are a deal-breaker, consider switching to a Bare Metal Cloud (BMC). BMC lets you host assets on a bare-metal dedicated server, a more reliable platform that also possesses cloud-like agility (near-instant scalability, deployments that require only a few clicks, various automation features, etc.).
Cloud Outage Causes
Cloud outages result from a number of causes both within and beyond the provider's control. Here's a list of the most common ones:
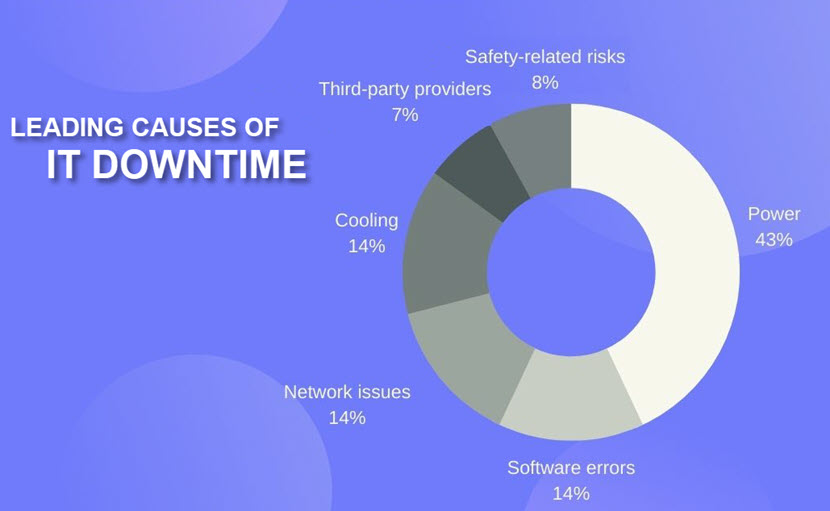
- Power outage: Power-related issues cause 43% of all cloud outages with significant downtime and financial loss. Uninterruptible power supply (UPS) failures are the number one cause of power incidents.
- Cybersecurity: Cyber attacks such as the Distributed Denial of Service (DDoS) overload data centers with incoming traffic. In that case, end-users cannot access the service via the same networking infrastructure. Other threats (such as ransomware or an SQL injection) may force the provider to shut services down and remedy the issue offline.
- Human error: A single incorrect command or a mistake with cabling can bring the entire IT infrastructure down. Human errors cause both physical and software issues that lead to outages.
- Technical problems: Cloud services rely on a complex system of hardware tech, so an error that manages to stay under the radar long enough can lead to a cloud outage.
- Software bugs: Glitches and bugs are common in cloud data centers. The usual culprits behind issues are data format bugs, fault-related bugs, timing bugs, and constant value bugs.
- Networking issues: Issues associated with network communication and third-party telco partners are another common cause of cloud outages.
- Maintenance: Scheduled maintenance and system upgrades sometimes lead to an outage, although end-users typically know about these occurrences in advance.
- Environmental causes: Events such as hurricanes, fires, lightning storms, and earthquakes also trigger cloud downtime, either by putting the facility in danger or by damaging the region's power grid.
- More complex deployments: More intricate deployment models (such as hybrid, distributed, and multi-cloud) complicate data center operations, creating more opportunities for errors.
When something goes wrong at a hosting facility, the availability of data and user-facing apps becomes a top priority. Our article on high availability offers an in-depth look at how companies ensure end-users do not feel the impact of data center issues.
What Happens When Cloud Goes Down?
In the best-case scenario, a cloud outage lasts only a few minutes and affects a small number of users or services. In the worst case, an outage paralyzes a client's business for half a day or longer. A company loses access to all cloud-based assets and stays cut off until the outage ends.
While threatening, mistakes by third-party providers were the cause of "only" 7% of severe outages in 2021. A severe outage must involve one (or several) of the following:
- Significant financial losses.
- Reputational damage.
- Compliance breaches.
- Loss of life.
While there are more pressing concerns (as shown in the donut chart below), remember that an average minute of downtime costs $5,600 (this per-minute figure goes to $9,000 for enterprises). If you are unprepared (i.e., you have no data backup strategies, disaster recovery, etc.), a cloud outage could grind your service to a halt and cause massive hits to the bottom line.
A company that keeps a small segment of operations in the cloud is less vulnerable to outages. For example, if you only host emails in the cloud, even a day-long outage is not catastrophic. You can wait out the incident or run apps with reduced functionality, a strategy that does not work if you use the cloud to run an IoT platform or perform payment processing.
In some cases, cloud outage leads to permanent data loss (the amount of lost data depends on the frequency of backups). Also, clients in strict industries are liable for legal fines if an outage leads to a data breach or leakage, so be careful when deciding what you keep in cloud storage.
What Can Users Do?
Here's what companies do to mitigate the impact of cloud outages:
- Remove single points of failure: Prepare a backup of every mission-critical IT component, either in an on-site server room or at a secondary provider. If the cloud goes down, you perform a failover (the process of switching to a standby server, hardware component, network, etc.) to ensure business continuity.
- Have a contingency plan: A disaster recovery plan outlines a step-by-step strategy for what the team does in case of an outage. This plan provides instructions for protecting data, performing failover, ensuring business continuity, and restoring operations. Timely planning for a cloud outage avoids wasting time in assessing the best course of action during downtime.
- Invest in a higher availability SLA: If your business-critical tasks cannot afford lengthy cloud outages, look for a higher availability Service Level Agreement (SLA), such as the one that guarantees 99.999% uptime (maximum of 5.25 minutes of downtime per year). These contracts are more expensive, but keeping your services online becomes a bigger priority for the cloud provider.
- Perform regular data backups: A backup ensures your team has a way to restore a recent version of files if a cloud outage corrupts or deletes a database. Ideally, backups should occur automatically and anywhere between once per hour to once per day (depending on mission-criticality).
- Detect outages ASAP: Any additional cloud monitoring capabilities your team sets up help identify an outage in real-time instead of waiting for the provider's notification. Here's a list of the best cloud monitoring tools to improve downtime detection and ensure timely failover.
PhoenixNAP's backup and Disaster-Recovery-as-a-Service (DRaaS) offerings help prepare both data and infrastructure for prolonged cloud outages, ensuring you can weather any amount of provider downtime.
Biggest Recent Cloud Outages
Cloud outages are unavoidable when using the cloud, and even the most popular providers (like Azure, AWS, and Google Cloud) are not immune to downtime. Let's look at some of the most significant cloud outages in recent history.
Azure Outage (October 2021)
In October 2021, Microsoft Azure suffered a disruption that took down virtual machine services for six hours. For the duration of the outage, many users were unable to deploy new VMs or update extensions. Basic service management operations (such as start, create, and delete) also led to errors.
The cause of the cloud outage was the inability of VM queries to retrieve the required version data of an artifact. A post-recovery report revealed that the software-based mistake occurred when Microsoft migrated one of its VM architectures.
Google Cloud Outage (November 2021)
Google Cloud went down for about two hours in mid-November last year, affecting the likes of:
- Home Depot.
- Snapchat.
- Etsy.
- Discord.
- Spotify.
Impacted websites displayed 404 errors when visitors tried to access them. Google reported that the cause for the cloud outage was a glitch in a network configuration responsible for load balancing.
AWS Outage (December 2021)
A large connection activity surge overwhelmed networking devices in one of AWS's flagship facilities, affecting various websites and apps. Some of the most notable "victims" were:
- Amazon's website.
- Prime Video.
- Netflix.
- IMDb.
- PlayStation Network.
The data center issue caused severe latency within internal AWS networks. Customer apps felt the ripple effects, suffering traffic delays or total shutdowns for about seven hours.
Two Subsequent IBM Outages (January 2022)
An issue with IBM's infrastructure affected cloud services in the Dallas region for over five hours. The in-house team resolved the problem but accidentally caused an additional hour-long issue with virtual private cloud. The secondary problem affected users across the globe, including the USA, Japan, Canada, and Germany.
AWS/Slack Outage (February 2022)
Slack suffered an outage of its AWS cloud resources in February which prevented normal use of the communication platform for five hours. Over 11,000 reported users were unable to:
- Send or receive messages.
- Upload files.
- Join channels.
- Launch the desktop app.
Slack's team never shared the reason behind the cloud outage and requested all affected users to restart the app and clear their cache following the recovery.
iCloud Outage (March 2022)
Fifteen major Apple services went down for four hours in March due to a cloud outage, including:
- App Store.
- Apple Maps.
- Apple TV.
Apple's corporate and retail systems went down, too. The company later revealed that the root cause was a problem related to the company's domain name system (DNS).
Google Cloud Outage (March 2022)
On March 8, 2022, users of Google Cloud suffered service errors for two and a half hours. Spotify and Discord were among those hit by the outage.
A change to the Traffic Director code for processing configurations caused the error. According to the post-recovery report, bad code changes neglected configuration data format migrations, so the platform inadvertently deleted the user's programming.
Atlassian Outage (April 2022)
The year's biggest Atlassian outage started on April 5 and ended on April 18 (although some users started restoring services by April 8). The company explained that the outage occurred because of inadequate team communication and a poorly-planned incident response plan.
Although this cloud outage lasted almost two weeks for some users, there were no reports of significant losses of client data. However, users of both Atlassian's flagship products, Trello and Jira, were affected by the issue.
Microsoft Azure Outage (June 2022)
On June 7, Azure customers could not connect to resources hosted in the East US 2 region (mainly Virginia). The outage lasted about twelve hours and did not affect consumers relying on zone-redundant infrastructure. Compromised services included:
- Application Insights.
- Log Analytics.
- Managed Identity Service.
- Media Services.
- NetApp Files.
The culprit was a sudden power oscillation in one of the local data centers, which caused Air Handling Units (AHUs) to shut down.
Cloudflare Outage (June 2022)
In June, an accidental outage at Cloudflare caused major disruptions that lasted an hour and a half, taking down popular sites such as:
- Discord.
- Shopify.
- Fitbit.
- Peloton.
The San Francisco-based vendor explained that the unplanned downtime resulted from a change to the network configuration in 19 of its data centers.
If public cloud outages are a concern, consider data repatriation or cloud repatriation. Repatriation takes cloud-based assets (data, apps, workloads, etc.) back on-site to bare metal.
Do Not Overlook the Value of Cloud Outage Planning
Examples of cloud outages in recent years send a clear message: even though the cloud is an IT game-changer, the tech is not foolproof. Companies that care about end-users and app availability must be ready for occasional downtime, which makes backup and disaster recovery (BDR) an integral part of using cloud-based resources.




