
Introduction
In today's market, even a brief interruption of service can lead to losing customer confidence and, eventually, to financial losses. This is especially true for businesses working in a sector like SaaS.
Using disaster recovery as a service in your business process is essential if you want to ensure high availability and business continuity. Failover and failback are some of the most commonly used disaster recovery methods.
In this tutorial, we will explain what failover and failback are, how they work, and what makes them different.

Note: Read our blog post for an in-depth explanation of what is Disaster Recovery, what its role is and how disaster recovery works.
Failover vs Failback: Summary
Whether it's due to an unexpected outage, a natural disaster, or planned maintenance, there are times when the production environment is temporarily unavailable. Failover and failback are disaster recovery mechanisms that help maintain business continuity in case of a sudden outage.
Failover is the process of switching to a designated backup recovery facility. This is usually a recovery site that contains a replicated copy of all the systems and data from your primary production site. Any changes made during a failover are saved to virtual storage.
Failback is a business continuity mechanism used when the primary production site is up and running again. Production is returned to its original (or new) site during a failback, and any changes saved in the virtual storage are synchronized.
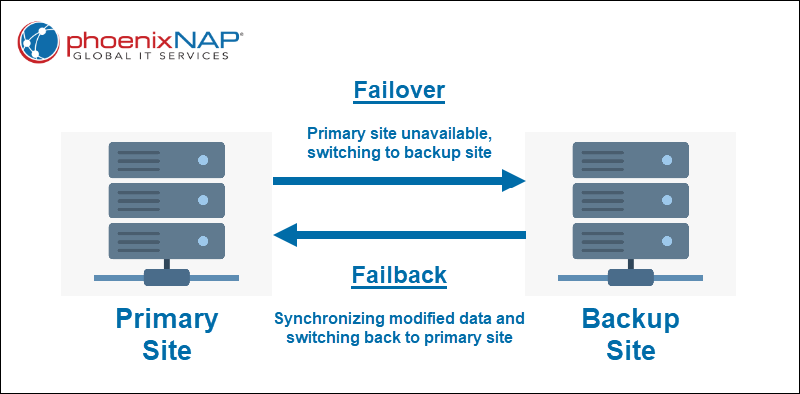
What is a Failover?
Failover is the process of seamlessly switching from a primary production site to a backup recovery site. A failover happens when the primary site fails due to an unexpected disaster or in case of planned maintenance.
For a failover to work, there must be a backup bare metal server or virtual machine that acts as the recovery site system, ready to replace the primary site in case of failure. Since failover is an essential step in disaster recovery, the backup systems themselves must be immune to failure.
Failover and disaster recovery in whole is required for systems that require constant availability. At the server level, the backup environment tracks the "pulse" of the primary server and performs an automated failover if it detects an outage.
How a Failover Works?
There are two ways to set up a failover system: an active-active and active-passive (or active-standby) configuration. Both setups require at least two nodes (servers or VMs) to work properly.
In an active-active setup, multiple nodes are running simultaneously. This allows them to share the workload and prevent any one node from overloading. If one node stops working, its workload is taken up by other active nodes until it reactivates.
An active-passive (active-standby) setup also includes multiple nodes, but not all of them are active at the same time. Once an active node stops working, a passive node is activated and acts as a failover node. When the primary node is functioning again, the backup node switches operations back to the primary node and becomes passive again.
Regardless of the failover method, both configurations require that each node has an identical configuration. This ensures consistency and stability when switching between sites.
Note: During a failover, all system workloads are transferred to the recovery site. Any changes made are saved to virtual storage.
What is a Failback?
Failback is the process of switching back to the primary site after the planned or unplanned disruption has been resolved. Failback usually follows failover as a part of a disaster recovery plan.
Failback is not the only way to finalize a failover. When working with virtual machines, you can perform a permanent failback, making the backup virtual machine the new primary site.
How a Failback Works?
During a failover state, admins interact with a backup site. Any changes made in that period are saved as change data.
Once a failback happens, synchronizing the primary and recovery sites involves copying change data from the recovery to the primary site. This prevents the need for a complete system copy, saving time and improving reliability.
Successfully performing a failback requires some preparation. Consider the following steps before switching back to the primary site:
- Check the quality and network bandwidth of the connection to the primary site.
- Check all data at the backup site for potential errors. This is especially important for critical files and documentation.
- Thoroughly test all primary systems before starting a failback.
- Prepare and implement a failback plan that minimizes downtime and user inconvenience.
Conclusion
After reading this article, you should have an understanding of failover and failback as disaster recovery methods.


